非線形方程式の求根問題
オイラー条件(式 5 )に予算制約を代入すると次式を得る.
\[
u'(w-a) = \beta(1+r)u'((1+r)a)
\tag{10}\]
状態変数 \(w\) を \(w_i\) と離散化して,それぞれの変数の役割を見てみると
\[
u'(\eqDescribe{w_i}{given} - \eqDescribe{a}{control}) =
\eqDescribe{\beta(1+r)}{parameter}u'(\eqDescribe{(1+r)}{parameter}\ \eqDescribe{a}{control})
\]
なので,未知変数は \(a\) だけである.そこで,式 10 を変形して次式で残差関数 (residual function) を定義する:
\[
R(a;w_i) \equiv
\beta(1+r)\frac{u'((1+r)a)}{u'(w_i-a)} - 1.
\tag{11}\]
式 11 を使うと,オイラー条件を満たす制御変数 \(a\) を見つける問題を,
\[
R(a;w_i) = 0
\]
となる \(a\) を探すという求根(ゼロ点)問題 (root-finding problem) に変換することができる.
一般に,オイラー条件を変換して得た残差関数(式 11 )は,複雑な形をした非線形方程式である可能性があるが,非線形方程式のゼロ点を探すアルゴリズムの研究は長い歴史を持つため,様々なアプローチが考案されている.
実装
求根問題は scipy.optimize.fsolve() 関数§ 3.3 のものを再び使用する.
まずはソルバーに渡す残差関数(式 11 )を実装しよう.残差関数内にある限界効用 (marginal utility) は
\[
u'(c) = c^{-\gamma}
\]
で与えられるので,Python で表すと次のようになる.
def marginal_util(c, gamma):return c ** (- gamma)
これを用いると残差関数は次のように実装できる.
§ 3.3 と同様に,ソルバーを使って各状態変数 \(w_i\) の下で最適貯蓄を求めていく.
1 = np.zeros(params.nw)for i, w_i in enumerate (params.grid_w):2 = lambda a: resid(a, w_i, params)3 = optimize.fsolve(resid_specified, x0= 0.01 )[0 ]print (f"最適貯蓄の配列: \n { opt_a} " )
1
各 \(w_i\) の下での最適貯蓄を格納する配列
2
optimize.fsolve() に渡すために,resid() を a だけの関数にする
3
我々が欲しい最適な \(a\) は optimize.fsolve() の返り値の最初の要素に格納されている
最適貯蓄の配列:
[0.03550089 0.07100178 0.10650266 0.14200355 0.17750444 0.21300533
0.24850621 0.2840071 0.31950799 0.35500888]
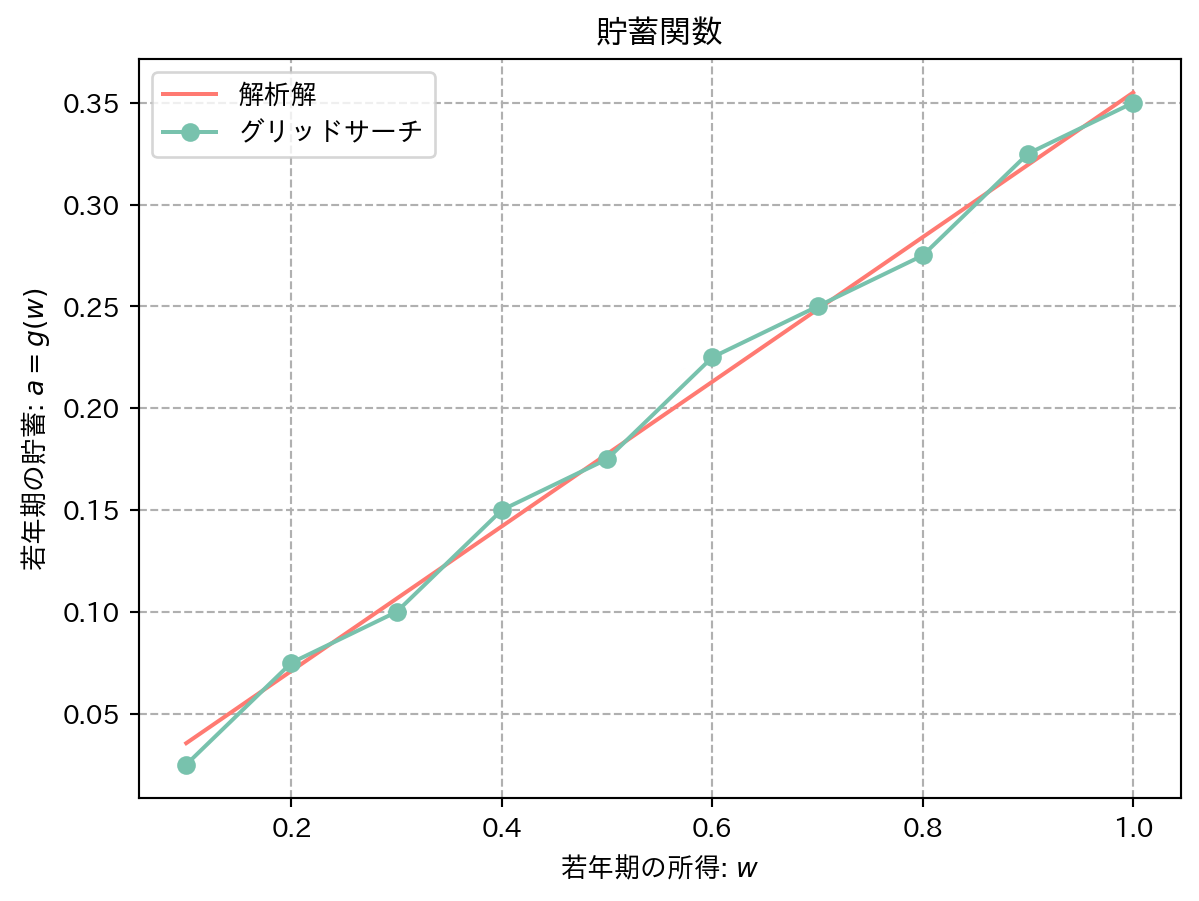
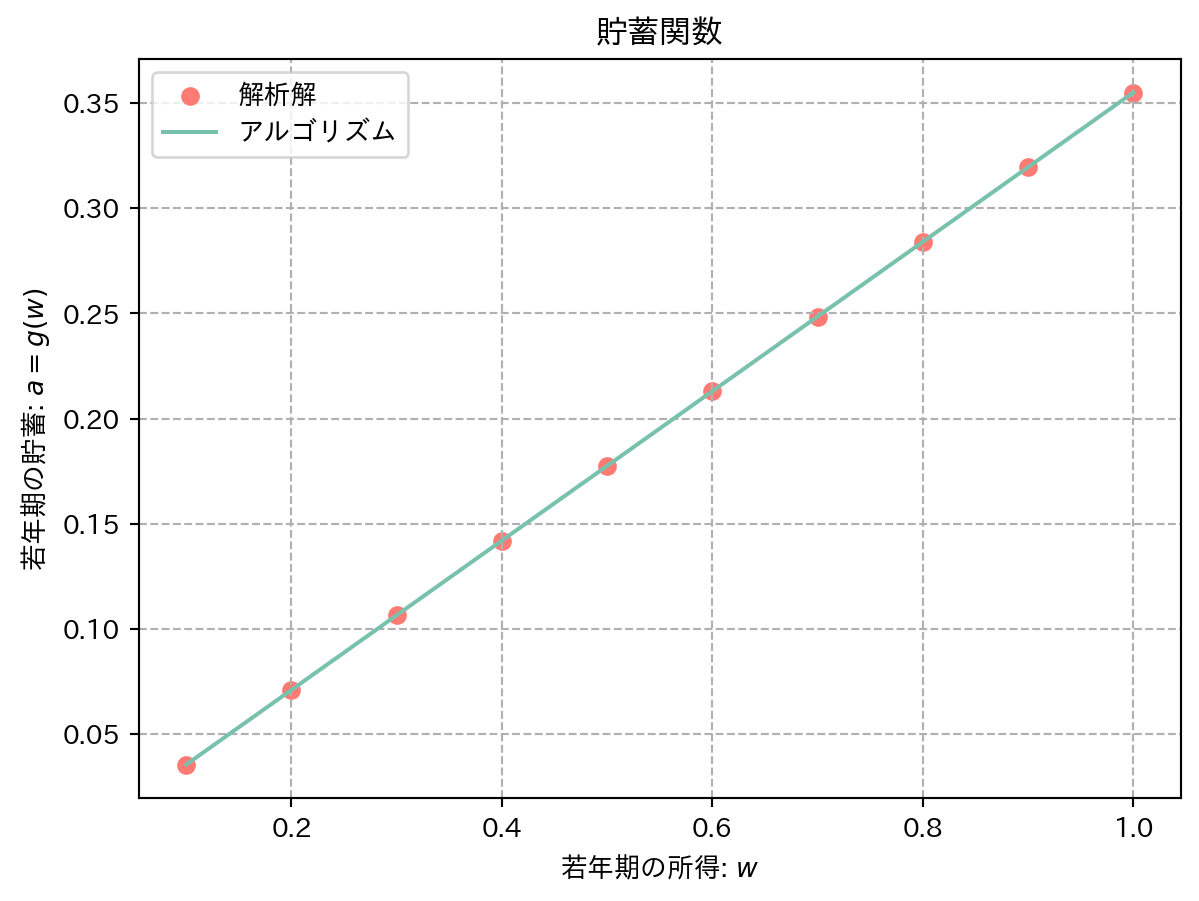
結果を図示した 図 6 を見ると,アルゴリズムで求めた解が解析解の直線上に乗っている様子がわかる.
= plt.subplots()= "--" )= "#FF7A72" ,label= "解析解" )= "#78C2AD" , label= "アルゴリズム" )set (title= "貯蓄関数" , xlabel= "若年期の所得: " + r"$w$" , ylabel= "若年期の貯蓄: " + r"$a=g(w)$" )pass
パラメトリックな近似:射影法
最適化(§ 3.3 )と求根アルゴリズム(§ 3.4.1 )を使った手法はどちらも,本来連続値をとる現在の所得水準 \(w\) を有限個に離散化して,そのグリッドポイント上で最適貯蓄を計算するという点は共通している.
これに対して,射影法 (projection method) では求めたい政策関数そのものをパラメトリックに近似するというアプローチをとる.
今考えている政策関数は若年期の所得 \(w\) を変数にとる貯蓄関数 \(a=g(w)\) である.貯蓄関数をパラメトリックに近似するとは、貯蓄関数を基底関数 (basis function) \(\{\Psi_m\}_{m=0}^M\) の線形結合 \(\hat{g}(w;\bm{\theta})\) で近似するということである.
\[
a = g(w) \approx \hat{g}(w;\bm{\theta}) = \sum_{m=0}^M \theta_m\Psi_m(w)
\tag{12}\]
ここで \(\bm{\theta} \equiv \Paren{\theta_m}_{m=0}^M\) は未知の \(M+1\) 次元係数ベクトルであり,推定する対象である.
この段階では,未知の貯蓄関数 \(g(w)\) はきっとパラメトリックな関数 \(\hat{g}(w;\bm{\theta})\) で表されるだろうと思っているに過ぎず,何も解決していない.
しかし,真の貯蓄関数 \(g(w)\) はオイラー条件(式 10 )を満たすので,それを近似した関数 \(\hat{g}(w;\bm{\theta})\) もできるだけオイラー条件を満たしておいて欲しいと思うのは自然な要請である.
つまり射影法とは,オイラー条件を満たす政策関数を探す問題を,近似関数 \(\hat{g}(w;\bm{\theta})\) ができるだけオイラー条件を満たすように係数ベクトル \(\bm{\theta}\) を決める問題に置き換える手法である.
以下では基底関数を \(\Psi_m(w) = w^m\) と指定し,貯蓄関数を次の多項式 (polynomial) で近似して議論を進める.
\[
a \approx \hat{g}(w;\bm{\theta}) = \sum_{m=0}^M \theta_m w^m
\tag{13}\]
ところで,上述の「できるだけオイラー条件を満たす」ことをどうやって評価すれば良いだろうか.ここで,§ 3.4.1 で定義した残差関数(式 11 )を思い出そう.
仮に近似関数 \(\hat{g}(w;\bm{\theta})\) が真の貯蓄関数 \(g(w)\) と完全に一致する場合は残差はゼロになり,うまく近似しているのであれば残差はゼロに近いはずである.つまり,
\[
R(\bm{\theta}; w) \equiv
\beta (1+r)\frac{u'((1+r)\hat{g}(w;\bm{\theta}))}{u'(w-\hat{g}(w;\bm{\theta}))} - 1 \approx 0
\tag{14}\]
が「あらゆる \(w\) で」成り立つ.
「」をつけたのは,実際に数値計算を行う際コンピュータは連続的な \(w\) を扱えないため,任意にとった評価点 \(\{w_i\}_{i=1}^N\) 上での残差がゼロに限りなく近くなるようなベクトル \(\bm{\theta}\) を見つける必要があるからである.
要素に評価点 \(w_i\) 上での残差 \(R(\bm{\theta}; w_i)\) を持つベクトルを \(\bm{R}(\bm{w}; \bm{\theta}) \equiv \Paren{R(\bm{\theta}; w_i)}_{i=1}^N\) とする. ただし,\(\bm{w} = \Paren{w_i}_{i=1}^N\) である.
\(\rho(\cdot, \cdot)\) を距離関数 (metric function) とすると,考えている問題は
\[
\bm{\theta}^* = \argmin_\bm{\theta} \rho(\bm{R}(\bm{w}; \bm{\theta}), \bm{0})
\tag{15}\]
と定式化できる.このように,評価点上でのみ距離を測る方法を選点法 (collocation method) と呼ぶ.
実装
カリブレーションは § 3.3 のものを再び使用する.
ここでは多項式 式 13 の次数を \(M=1\) として,1次関数 \(\hat{g}(w;\bm{\theta}) = \theta_0 + \theta_1 w\) で政策関数を近似しよう.
各評価点 \(w_i\) での近似値 \(\hat{g}(w_i; \bm{\theta})\) を要素にもつ列ベクトルを \(\widehat{\bm{g}}\) とすると
\[
\widehat{\bm{g}} = \Paren{\hat{g}(w_i;\bm{\theta})}_{i=1}^N =
\begin{pmatrix} \theta_0 + \theta_1 w_1 \\ \vdots \\ \theta_0 + \theta_1 w_i \\ \vdots \\ \theta_0 + \theta_1 w_N \end{pmatrix} =
\eqDescribe{\begin{pmatrix} 1 & w_1 \\ \vdots & \vdots \\ 1 & w_i \\ \vdots & \vdots \\ 1 & w_N \end{pmatrix}}{denoted by X below}
\begin{pmatrix} \theta_0 \\ \theta_1 \end{pmatrix}
\]
と書けるが,これを実装すると次のようになる.
def approx_g(theta: np.ndarray, w: np.ndarray) -> np.ndarray:= len (theta)= len (w)1 = np.zeros((nw, dim))for j in range (dim):2 = w ** jreturn X @ theta
1
行列 \(X\) を初期化
2
行列 \(X\) を作成
次に,残差関数 resid()(Code 1 )を利用して,式 14 に従って残差ベクトル \(\bm{R}(\bm{w}; \bm{\theta})\) を実装する.
def resid_vec(theta, params):1 = approx_g(theta, params.grid_w)= np.zeros(nw)for g, w_i, i in zip (g_hats, params.grid_w, np.arange(nw)):= resid(g, w_i, params)return R
1
貯蓄の近似値ベクトル \(\bm{\hat{g}}\) を計算
ここで,距離関数 \(\rho\) にユークリッド距離を採用すると,考えている問題(式 15 )は残差二乗和を最小にする \(\bm{\theta}\) を見つける非線形最小二乗法に帰着する.
非線形最小二乗法は scipy.optimize.least_squares()fun 引数に残差ベクトルを計算する関数を渡せば良い.
def projection(params, initial_guess= [0.1 , 0.35 ]):1 = lambda theta: resid_vec(theta, params)= optimize.least_squares(fun= resid_specified, x0= initial_guess, method= "lm" )2 = approx_g(result.x, params.grid_w)return result.x, result.success, estimate_g
1
optimize.least_squares() に渡すために,resid_vec() を theta だけの関数にする
2
推定された \(\widehat{\bm{\theta}}\) の下での近似関数 \(\hat{g}(w; \widehat{\bm{\theta}})\) を求める
では,実装した projection() 関数を使って射影法を実際に行おう.
= projection(params)print (f"convergence: { result[1 ]} " )print (f"The estimated parameter: { result[0 ]} " )
convergence: True
The estimated parameter: [-1.90171907e-10 3.55008878e-01]
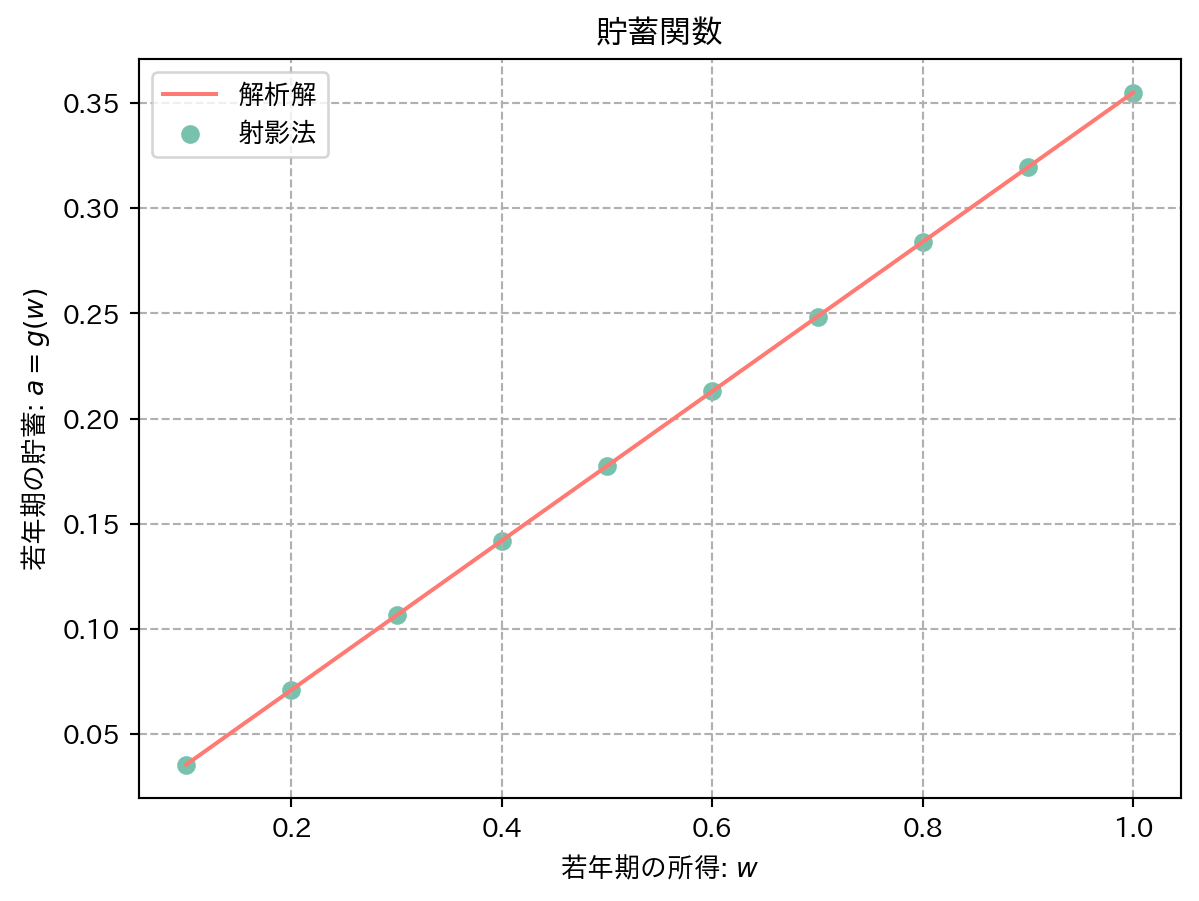
解析解(式 7 )によれば,切片はゼロで,傾きは \(1/1+(1+r)\{\beta(1+r)\}^{-1/\gamma}\) から計算すると 0.355 であるから,非常に精度良く近似することができている.
推定されたパラメータ \(\widehat{\bm{\theta}}\) の下での近似関数のグリッド \(\widehat{\bm{g}}(\bm{w}; \widehat{\bm{\theta}})\) と真の貯蓄関数を可視化したものが 図 7 である.
= plt.subplots()= "--" )= "#FF7A72" ,label= "解析解" )2 ], c= "#78C2AD" , label= "射影法" )set (title= "貯蓄関数" , xlabel= "若年期の所得: " + r"$w$" , ylabel= "若年期の貯蓄: " + r"$a=g(w)$" )pass